In This Section we will be focusing on different methods to perform row wise mean of the pandas dataframe. i.e., Row wise mean of all the numeric column in pandas python also Row wise mean of specified columns in pandas python. There are multiple ways to do it, we have used functions like iloc(), values() along with mean() function to achieve the same. let’s look at each of these cases in pandas with an example for each.
- Row wise mean of all numeric columns in pandas
- Row wise mean of specific columns in pandas
- Row wise mean of pandas dataframe by column index slicing
- Row wise mean of pandas dataframe by column index using list
- Row wise mean of pandas dataframe by column name (label)
Create Dataframe:
## create dataframe
import pandas as pd
import numpy as np
d = { 'Name':['Alisa','Bobby','Cathrine','Jodha','Raghu','Ram'],
'Maths':[76,73,83,93,89,94],
'Science':[85,41,55,75,81,97],
'Geography':[78,65,55,88,87,98]}
df = pd.DataFrame(d,columns=['Name','Maths','Science','Geography'])
df
resultant dataframe is
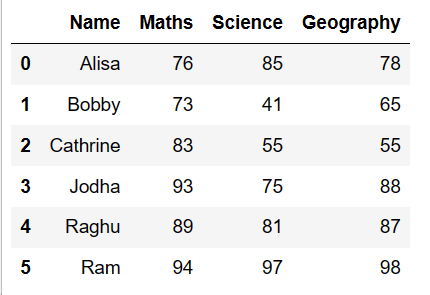
Row wise mean of all numeric columns in pandas
Row wise mean of all numeric columns in pandas is performed using df.mean() function with axis =1 by passing parameter numeric_only=True. Which will take up all the numeric column and will do row wise mean and will be stored under new column named ‘Average’ as shown below.
####### row wise mean of all numeric columns in pandas df['Average'] = df.mean(axis=1, numeric_only=True) df
resultant dataframe is
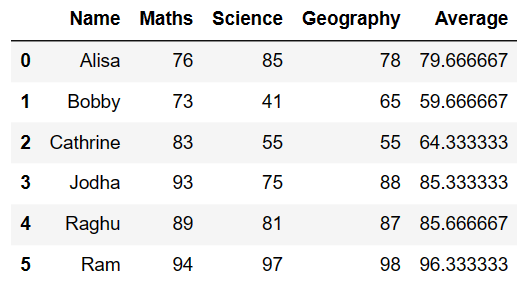
Row wise mean of specific columns in pandas
Row wise mean of specific columns in pandas is performed using mean() function with axis =1 by filtering only the specific column using iloc. Which will take up the specific numeric column and will do row wise mean and will be stored under new column as shown below.
####### row wise mean of specific numeric columns in pandas df['non_maths_average']=df.iloc[:,2:4].mean(axis = 1) df
Science and Geography Score is Averaged up and new column “non_maths_average” is created so resultant dataframe is
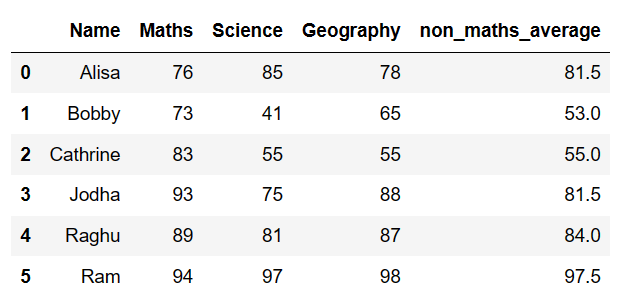
Row wise mean of pandas dataframe by column index slicing : Method 1
Row wise mean of columns in pandas is performed using mean() function with axis =1 by filtering only the specific column using iloc. Which will take up the specific numeric column and will do row wise mean and will be stored under new column as shown below. If the columns are in a sequential position, you can use a slice object.
####### row wise mean by column index slicing in pandas : Method 1 ##If the columns are in a sequential position, you can use a slice object. df['Average']=df.iloc[:,1:4].mean(axis = 1) df
Columns which is sliced by specified index is averaged up and new column “Average” is created so resultant dataframe is
Row wise mean of pandas dataframe by column index slicing : Method 2
Row wise mean of columns in pandas is performed using mean() function with axis =1 by filtering only the specific column using df.values. Which will take up the specific numeric column and will do row wise mean and will be stored under new column as shown below. If the columns are in a sequential position, you can use a slice object.
####### row wise mean/average by column index slicing in pandas : Method 2 #If the columns are in a sequential position, you can use a slice object. ##You can also use the DataFrame as a NumPy array object, by using df.values. df['Average']=df.values[:,1:4].mean(axis = 1) df
Columns which is sliced by specified index is averaged up and new column “Average” is created so resultant dataframe is
Row wise mean of pandas dataframe by column index using list: Method 1
If the columns are not in a sequential position, you can use a list. Keep in mind that this subsetting method is twice as slow as using a slice. Column index is passed as a list and then row wise mean is performed with mean() function and axis =1 by will be stored under new column as shown below
####### row wise mean/average by column index using list in pandas : Method 1 df['Average']=df.iloc[:,[1,2,3]].mean(axis = 1) df
Columns which is indexed using is averaged up and new column “Average” is created so resultant dataframe is
Row wise average of pandas dataframe by column index using list: Method 2
If the columns are not in a sequential position, you can use a list. Column index is passed as a list and then row wise mean is performed with mean() function and axis =1 by will be stored under new column as shown below
####### row wise mean by column index using list in pandas : Method 2 df['Average']=df.values[:,[1,2,3]].mean(axis = 1) df
index is passed as list and is summed up at row level and new column “Average” is created so resultant dataframe is
Row wise mean of pandas dataframe by column name (label): Method 1
Column names are filters using .loc and mean() function with axis=1 will perform the row wise mean operation
####### row wise mean by column name (label) slicing in pandas : Method 1 df['Average']=df.loc[:,['Maths', 'Science', 'Geography']].mean(axis = 1) df
OR
df['Average']=df[['Maths', 'Science', 'Geography']].mean(axis = 1) df
new column “Average” is created which has row wise mean, so resultant dataframe is
Row wise Average of pandas dataframe by column name (label): Method 2
Turn each column into a pandas Series and sum them individually will yield row wise sum and then divide by the count. It’s faster than the list subset but not as fast as the slice subset.
df['Average']= (df['Maths'] + df['Science'] + df['Geography'])/3 df
new column “Average” is created which has row wise mean, so resultant dataframe is





